Home | Gokhan Atil's Technology Blog
It’s a common question to ask how to disable caching in Snowflake for testing. Although it’s a very straightforward question, the answer is a bit complicated, and we need to understand the cache layers of Snowflake to answer this question.
There are three cache layers in Snowflake:
1) Metadata cache: The Cloud Service Layer has a cache for metadata. It impacts compilation time and metadata-based operations such as SHOW command. The users may see slow compilation times when the metadata cache required by their query is expired. This cache cannot be turned off and is not visible to end-users if the metadata cache is used.
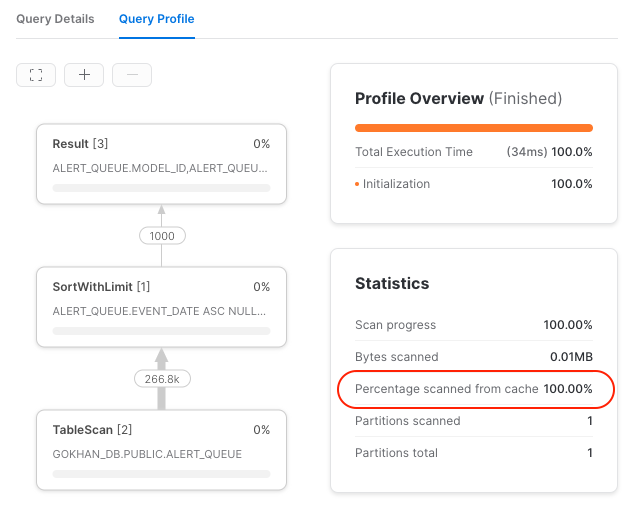
2) Warehouse cache: Each node in a warehouse has an SSD storage. Snowflake caches recently accessed micro-partitions (from the Cloud storage) in this local SSD storage on the warehouse nodes. So running similar queries may use these cached micro-partitions instead of accessing remote storage. This cache cannot be turned off, but it’s possible to see how much warehouse cache is used via the query profile:
This post contains some sample PySpark scripts. During my “Spark with Python” presentation, I said I would share example codes (with detailed explanations). I posted them separately earlier but decided to put them together in one post.
Grouping Data From CSV File (Using RDDs)
For this sample code, I use the u.user file of MovieLens 100K Dataset. I renamed it as “users.csv”, but you can use it with the current name if you want.

The account usage view has two views related to stages: STAGES and STAGE_STORAGE_USAGE_HISTORY. The STAGES view helps list all the stages defined in your account but does not show how much storage each stage consumes. The STAGE_STORAGE_USAGE_HISTORY view shows the total usage of all stages but doesn’t show detailed use.
I wrote the following script to list the internal stages (and their occupied storage) in all available databases:
Amazon Quantum Ledger Database is a fully managed ledger database that tracks all changes in user data and maintains a verifiable history of changes over time. It was announced at AWS re:Invent 2018 and is now available in five AWS regions: US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo).
You may ask why you would like to use QLDB (a ledger database) instead of your traditional database solution. We all know that it’s possible to create history tables for our fact tables and keep them up to date using triggers, stored procedures, or even with our application code (by writing changes of the main table to its history table). You can also say that your database has write-ahead/redo logs, so it’s possible to track and verify the changes in all your data as long as you keep them in your archive. On the other hand, this will create an extra workload and complexity for the database administrator and the application developer. At the same time, it does not guarantee that the data was intact and reliable. What if your DBA directly modifies the data and history table after disabling the triggers and altering the archived logs? You may say it’s too hard, but you know that it’s technically possible. In a legal dispute or a security compliance investigation, this might be enough to question the integrity of the data.