When it comes to managing large data sets in Snowflake, Automatic Clustering is one of the key features that can help improve performance. But before we dive into how it works, let’s first take a look at how Snowflake stores data and what partition pruning means.
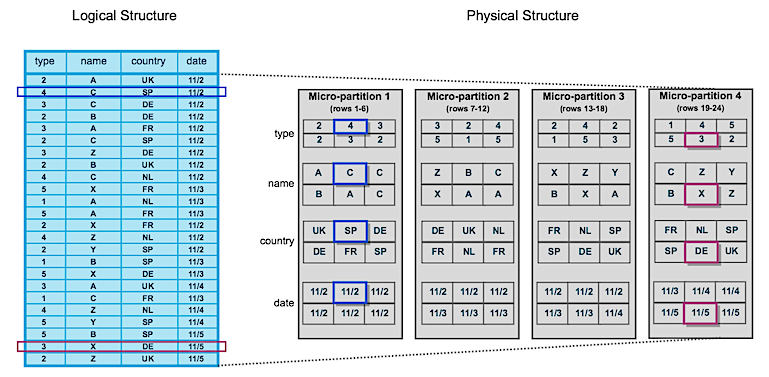
Snowflake stores data in the tables as micro-partitions. These are small, contiguous units of storage that Snowflake can use to quickly access the data you need. Snowflake maintains clustering metadata for the micro-partitions in a table, including min and max values of columns in the micro-partition. When you run a query, Snowflake examines the filters to determine which partitions contain the relevant data. For example, if a query filters data by a specific date range, Snowflake can exclude partitions that do not contain data within that range. This is called “partition pruning”. Partition pruning is particularly effective for large and complex data sets, where the amount of data that needs to be scanned can be prohibitively high.
Automatic Clustering continually manages reclustering operations, and redistributse data to micro-partitions based on clustering keys. This will help Snowflake to read fewer micro-partitions to access the relevant data, resulting in faster query processing times and lower costs. When similar data is grouped together, compression algorithms can also work more effectively, further reducing the amount of data that needs to be scanned and processed.
In order to assess the benefits of automatic clustering in Snowflake and its impact on partition pruning and query performance, I will do some tests. First, I create a table with some dummy data:
CREATE or REPLACE TABLE sales (
sales_date DATE,
customer_id INTEGER,
payload VARCHAR
) AS SELECT dateadd( 'day', uniform(0,450, random(0)), '2022-01-01' ),
uniform(0,10000, random(0)),
randstr( 1000, random(0) )
FROM TABLE(generator(ROWCOUNT => 1000000 ));
In the current scenario, it is worth noting that no specific clustering key was defined during the creation of the table, leading to the data being organized based on the order in which it arrived. To assess the effectiveness of micro-partition pruning, I disabled the result cache (a mechanism that stores query results for subsequent use), and run the following statements:
SELECT COUNT( distinct customer_id) FROM sales WHERE sales_date = '2023-03-10';
SELECT operator_statistics:pruning FROM TABLE(GET_QUERY_OPERATOR_STATS(LAST_QUERY_ID())) WHERE operator_type='TableScan';
+----------------------------------------------------------+
| OPERATOR_STATISTICS:PRUNING |
+----------------------------------------------------------+
| { "partitions_scanned": 41, "partitions_total": 41 } |
+----------------------------------------------------------+
Upon examining the last query, it becomes apparent that our table comprises 41 micro-partitions, and despite our query targeting data from a single day (‘2023-03-10’), all micro-partitions are being scanned.
In order to demonstrate the functionality of automatic clustering, I create a duplicate of the table and define a clustering key on the sales_date column. It is important to note that Snowflake undertakes automatic reclustering in the background, but the process does not initiate immediately. Therefore, I will allow a brief interval for the maintenance to commence. Subsequently, I will execute queries against the automatic_clustering_history function at regular intervals until confirmation of the completion of the reclustering task:
CREATE or REPLACE TABLE sales_clustered AS SELECT * FROM sales;
ALTER TABLE sales_clustered CLUSTER BY (sales_date);
SELECT * FROM table(information_schema.automatic_clustering_history( TABLE_NAME => 'sales_clustered' ));
After I see the maintance is completed, I re-run the queries I did earlier on non-clustered query:
SELECT COUNT( distinct customer_id) FROM sales WHERE sales_date = '2023-03-10';
SELECT operator_statistics:pruning FROM TABLE(GET_QUERY_OPERATOR_STATS(LAST_QUERY_ID())) WHERE operator_type='TableScan';
+---------------------------------------------------------+
| OPERATOR_STATISTICS:PRUNING |
+---------------------------------------------------------+
| { "partitions_scanned": 2, "partitions_total": 41 } |
+---------------------------------------------------------+
The implementation of clustering has effectively reduced the overall number of micro-partitions required to access the relevant data. I would like to remind that while Automatic Clustering is not essential for benefiting from partition pruning, it proves highly advantageous in maintaining the optimal structure of your table, enabling queries to leverage the advantages of partition pruning. It’s also important that choosing the right clustering key plays a critical role in achieving optimal performance. Here are some guidelines to follow when selecting a clustering key:
- Identify the columns used in your most frequent queries: The clustering key should be chosen based on the columns that are most commonly used in your queries. This will ensure that the data is physically organized in a way that optimizes query performance.
- Choose columns with high cardinality: Columns with high cardinality (i.e. a large number of distinct values) make better clustering keys because they allow for more precise grouping of similar data, which in turn results in more efficient query processing, but avoid very high cardinality will may increase maintenance costs.
- Select columns with a good distribution of values: A good clustering key should have a distribution of values that is roughly uniform. If a column has a skewed distribution, it may result in unevenly distributed data and suboptimal query performance.
- Consider the size of the table: You don’t need to define a clustering key for small tables (there is no strict rule but I don’t recommend automatic clustering for the tables under 100 GB).
- Test different clustering keys: It may be necessary to test different clustering keys to determine which one provides the best performance for your specific workload.
In conclusion, Automatic Clustering is a powerful feature in Snowflake that can help improve query performance and reduce costs. By clustering your data, you can ensure that similar data is grouped together, making it easier to access. If you’re using Snowflake for data warehousing, be sure to take advantage of this powerful feature to get the most out of your data!