I wrote a simple AWS Lambda function to demonstrate how to connect an Oracle database, gather the tablespace usage information, and send these metrics to CloudWatch. First, I wrote this lambda function in Python, and then I had to re-write it in Java. As you may know, you need to use the cx_oracle module to connect Oracle Databases with Python. This extension module requires some libraries shipped by Oracle Database Client (oh God!). It’s a little bit tricky to pack it for the AWS Lambda.
Here’s the main class which a Lambda function can use:
In this blog post, I’ll show how to build a three-node Cassandra cluster on Docker for testing. I’ll use official Cassandra images instead of creating my images, so all processes will take only a few minutes (depending on your network connection). I assume you have Docker installed on your PC, have an internet connection (I was born in 1976, so it’s normal for me to ask this kind of question), and have at least 8 GB RAM. First, we need to assign about 5 GB RAM to Docker (in case it has less RAM) because each node will require 1.5+ GB RAM to work properly.
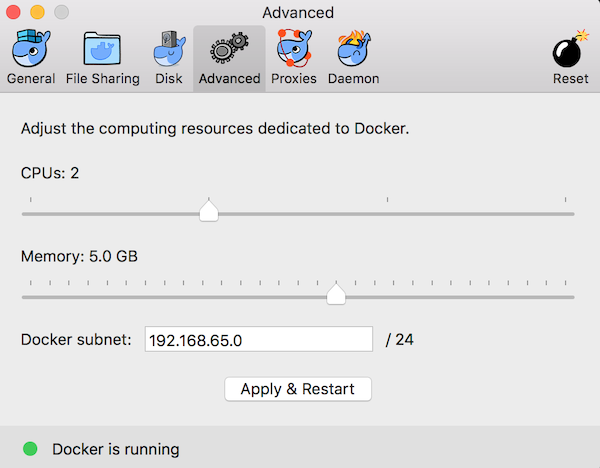
Open the docker preferences, click the advanced tab, set the memory to 5 GB or more, and click “apply and restart” docker service. Launch a terminal window, and run the “docker pull cassandra” command to fetch the latest official Cassandra image.
I’ll use cas1, cas2, cas3 as the node names, and the name of my Cassandra cluster will be “MyCluster” (a very creative and unique name). I’ll also configure cas1 and cas2 like they are placed in datacenter1 and cas3 like it’s placed in datacenter2. So we’ll have three nodes, two of them in datacenter1 and one in datacenter2 (to test Cassandra’s multi-DC replication support). For multi-DC support, my Cassandra nodes will use “GossipingPropertyFileSnitch”. This extra information can be passed to docker containers using environment variables (with -e parameter).
As you know, Weblogic is a part of the Enterprise Manager Cloud Control environment, and it’s automatically installed and configured by the EM installer. The Enterprise Manager asks you to enter a username and password for Weblogic administration. This information is stored in secure files; you usually do not need them unless you use the Weblogic console. So it’s easy to forget this username and password, and that’s what happened to me. Fortunately, there’s a way to recover them without resetting a new user/password. Here are the steps:
First, we need to know the DOMAIN_HOME directory. My OMS is located in “/u02/Middleware/oms”. You can find yours if you read “/etc/oragchomelist”. If the full path of OMS is “/u02/Middleware/oms”, the middleware home is “/u02/Middleware/”. Under my middleware home, I need to go GCDomains folder:
oracle@db-cloud /$ cd /u02/Middleware
oracle@db-cloud Middleware$ cd gc_inst/user_projects/domains/GCDomain
Then we get the encrypted information from boot.properties file:
oracle@db-cloud GCDomain$ cat servers/EMGC_ADMINSERVER/security/boot.properties
# Generated by Configuration Wizard on Wed Jun 04 10:22:47 EEST 2014
username={AES}nPuZvKIMjH4Ot2ZiiaSVT/RKbyBA6QITJE6ox56dHvk=
password={AES}krCf4h1du93tJOQcUg0QSoKamuNYYuGcAao1tFvHxzc=