Amazon Quantum Ledger Database is a fully managed ledger database that tracks all changes in user data and maintains a verifiable history of changes over time. It was announced at AWS re:Invent 2018 and is now available in five AWS regions: US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo).
You may ask why you would like to use QLDB (a ledger database) instead of your traditional database solution. We all know that it’s possible to create history tables for our fact tables and keep them up to date using triggers, stored procedures, or even with our application code (by writing changes of the main table to its history table). You can also say that your database has write-ahead/redo logs, so it’s possible to track and verify the changes in all your data as long as you keep them in your archive. On the other hand, this will create an extra workload and complexity for the database administrator and the application developer. At the same time, it does not guarantee that the data was intact and reliable. What if your DBA directly modifies the data and history table after disabling the triggers and altering the archived logs? You may say it’s too hard, but you know that it’s technically possible. In a legal dispute or a security compliance investigation, this might be enough to question the integrity of the data.
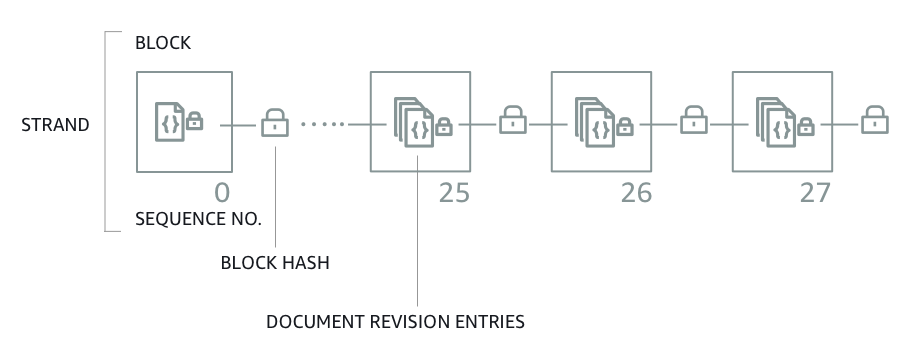
QLDB solves this problem with a cryptographically verifiable journal. When an application needs to modify data in a document, the changes are logged into the journal files first (WAL concept). The difference is that each block is hashed (SHA-256) for “verification” and has a sequence number to specify its address within the journal. QLDB calculates this hash value using the journal block’s content and the previous block’s hash value. So the journal blocks are chained by the hash values! The QLDB users do not have access to the immutable logs. If someone modifies data, they also need to update the journal blocks related to the data. This will cause a new hash to be generated for the journal block, and all the following blocks will have a different hash value than before.
As a devil’s advocate, you may wonder, “what happens if my data is modified without my permission and all the journal blocks are regenerated with new hash values”. It’s a very unlikely situation, but what if it happens? Honestly, this was my first question when I heard about the chain mechanism between the journal blocks. QLDB lets you download (and store) the last generated hash value (the digest), and this digest can be used to verify all previously committed transactions. So you have the key (the digest) to verify the integrity of the data. If any change is made to your journals or your data, even a bite changes, the digest will be different and not match yours!
What else do you need to know about QLDB?
- Journal-first: The system of record is the journal instead of the table storage.
- It’s immutable. You can see all history of data (even deleted data) because nothing can be deleted from the journal.
- Cryptographically verifiable: Hash-chaining provides data integrity.
- Highly scalable: It’s serverless, and you don’t need to maintain the underlying structure or resources.
- Easy to use: Supports PartiQL – SQL-compatible access to relational, semi-structured, and nested data.
- Document based: All records are stored in Amazon Ion format.
If you create a ledger, you’ll see that you can access data in two ways: Write a Java application or use the query editor. Unfortunately, there’s no “data import” tool or a command line client for now. So I wrote a basic command line tool which you can download the JAR file and the sources from the GitHub repository:

It supports importing CSV files to the existing tables in your ledger. Of course, it’s just a sample application and not designed for production work. To be able to use it, you need to configure your AWS CLI and set the region where your QLDB ledger resides.
After that, you can run it with “java -jar qldbcli.jar -l LEDGERNAME” (My ledger name is Deneme):
java -jar qldbcli.jar -l Deneme
----------------------------------------------------------
QLDB "the missing" Command Line Client v0.2 by Gokhan Atil
----------------------------------------------------------
PartiQL (Deneme) > select * from Vehicle
VIN,Type,Year,Make,Model,Color
"3HGGK5G53FM761765","Motorcycle",2011,"Ducati","Monster 1200","Yellow"
"1HVBBAANXWH544237","Semi",2009,"Ford","F 150","Black"
"KM8SRDHF6EU074761","Sedan",2015,"Tesla","Model S","Blue"
"1C4RJFAG0FC625797","Sedan",2019,"Mercedes","CLK 350","White"
"1N4AL11D75C109151","Sedan",2011,"Audi","A5","Silver"
If you want to quit from the client, you can use the “quit” command, and if you’re going to connect to another ledger, you can use the “CONN LedgerName” command. I usually use it for exporting/importing sample data between my tables. You can export your ledger table as CSV. All you need is to run a SELECT query with the “-q” parameter and then redirect the output to a file:
java -jar qldbcli.jar -l Deneme -q "SELECT * FROM Vehicle" > Vehicle.csv
You can also import data from a CSV file to a table you created on the ledger (Please note that I created the NewVehicle table by running the “CREATE TABLE NewVehicle” PartiQL command before running the import). The application expects you to give the filename (with “-f” parameter) and the target table (with “-t” parameter):
java -jar qldbcli.jar -l Deneme -f Vehicle.csv -t NewVehicle
You can enable verbose mode to debug connection or the errors you get with PartiQL commands by the “-v” parameter:
java -jar qldbcli.jar -l Deneme -v
Please keep in your mind that the ledger, table, and field names are all case-sensitive. As I said, my sample application is not designed to use for production, so please do not expect to use it to import millions of records. On the other hand, if you examine the source codes, it might help you to write your own QLDB application.