When it comes to managing large data sets in Snowflake, Automatic Clustering is one of the key features that can help improve performance. But before we dive into how it works, let’s first take a look at how Snowflake stores data and what partition pruning means.
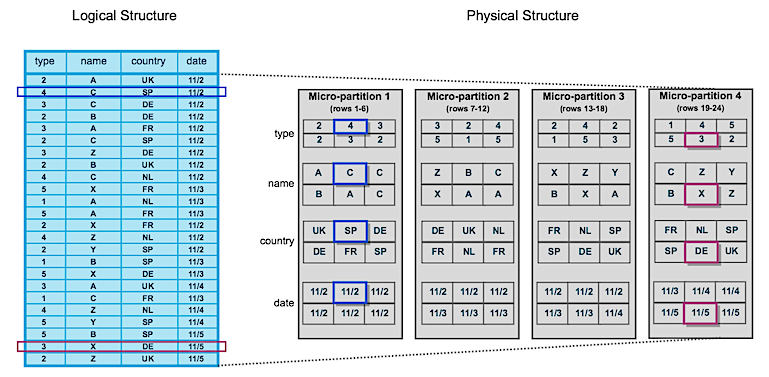
Snowflake stores data in the tables as micro-partitions. These are small, contiguous units of storage that Snowflake can use to quickly access the data you need. Snowflake maintains clustering metadata for the micro-partitions in a table, including min and max values of columns in the micro-partition. When you run a query, Snowflake examines the filters to determine which partitions contain the relevant data. For example, if a query filters data by a specific date range, Snowflake can exclude partitions that do not contain data within that range. This is called “partition pruning”. Partition pruning is particularly effective for large and complex data sets, where the amount of data that needs to be scanned can be prohibitively high.
When it comes to managing and analyzing large amounts of data, traditional data warehouses have been the go-to solution for decades. But in recent years, a new challenger has emerged: Snowflake. So, what exactly is Snowflake, and how does it differ from traditional data warehouses?
To understand the differences, it’s important to first define what we mean by “traditional data warehouse.” Essentially, a traditional data warehouse is a large repository of structured data that’s been preprocessed, organized, and optimized for querying and analysis. Typically, data is loaded into the warehouse from a variety of sources, such as transactional databases, flat files, or external data feeds. The data is then transformed, cleaned, and loaded into the warehouse using ETL (extract, transform, load) processes.
Snowflake, on the other hand, is a cloud-based data warehouse that takes a different approach. Rather than requiring users to provision and manage their own hardware and software infrastructure, Snowflake is provided as a service. This means that all of the hardware, software, and networking is managed by Snowflake, allowing users to focus on analyzing their data rather than managing their infrastructure.
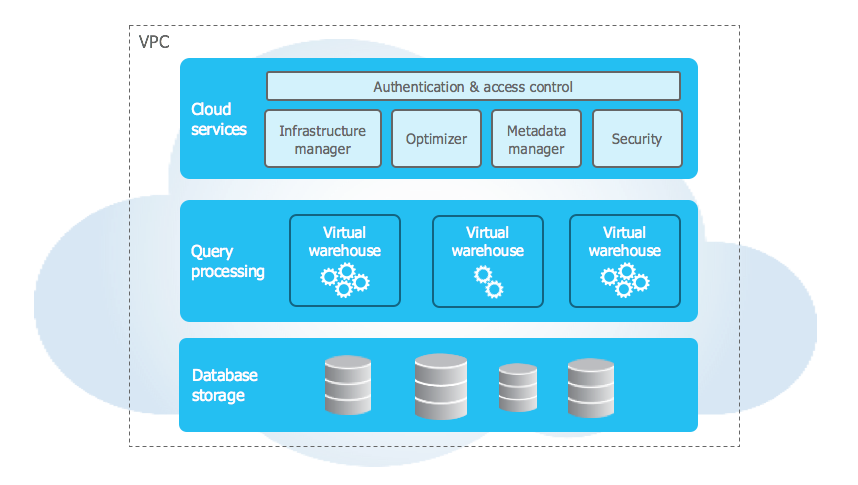
One of the key differences between Snowflake and traditional data warehouses is their architecture. Traditional data warehouses are typically implemented using a “shared-nothing” architecture, which means that data is partitioned and distributed across multiple nodes, each with its own CPU, memory, and storage. In contrast, Snowflake uses a hybrid of traditional shared-disk and shared-nothing architectures. Snowflake stores all data in a central repository and accessed using a virtual warehouse. This allows for greater flexibility and scalability, as users can scale their virtual warehouse up or down depending on their needs, without worrying about the underlying hardware.
It’s a common question to ask how to disable caching in Snowflake for testing. Although it’s a very straightforward question, the answer is a bit complicated, and we need to understand the cache layers of Snowflake to answer this question.
There are three cache layers in Snowflake:
1) Metadata cache: The Cloud Service Layer has a cache for metadata. It impacts compilation time and metadata-based operations such as SHOW command. The users may see slow compilation times when the metadata cache required by their query is expired. This cache cannot be turned off and is not visible to end-users if the metadata cache is used.
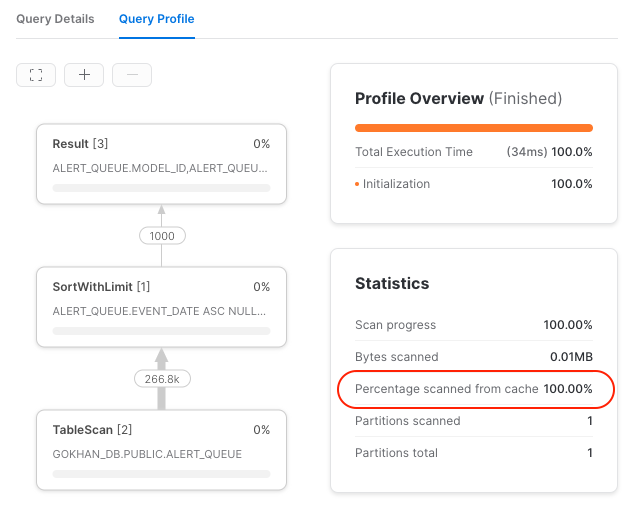
2) Warehouse cache: Each node in a warehouse has an SSD storage. Snowflake caches recently accessed micro-partitions (from the Cloud storage) in this local SSD storage on the warehouse nodes. So running similar queries may use these cached micro-partitions instead of accessing remote storage. This cache cannot be turned off, but it’s possible to see how much warehouse cache is used via the query profile:
This post contains some sample PySpark scripts. During my “Spark with Python” presentation, I said I would share example codes (with detailed explanations). I posted them separately earlier but decided to put them together in one post.
Grouping Data From CSV File (Using RDDs)
For this sample code, I use the u.user file of MovieLens 100K Dataset. I renamed it as “users.csv”, but you can use it with the current name if you want.
